![]() The
WSCR Archive
The
WSCR Archive
![]()
[The
following paper was originally prepared for the Conference of the
Centre for Critical Realism and the International Association for
Critical Realism, University of Örebro, Sweden, August 1999. It
is archived here with the kind permission of the author, who retains
the copyright. A copy of Developing
Open-Systems Interpretations of Path Analyses is also available
on Dr. Olsen's Web site.]
Developing Open-Systems Interpretations of Path Analyses: Fragility Analysis Using Farm Data From India
By Dr.
Wendy K. Olsen
Lecturer
in Quantitative Development Economics
University
of Bradford, Bradford
Abstract
Post-empiricists
and post-structuralists can use statistical work as a way of telling
stories that constructively contribute to knowledge and social
transformation. These stories may challenge or complement existing
orthodoxies (dominant narratives) but they also provide an
evidence-based source of ideas. However inferences from survey data
must be couched in a subjunctive tense, or very carefully couched in
a realist interpretation of the data creation process and underlying
social processes. I set out some details of one statistical method,
path analysis, which uses several multiple regressions to improve
upon the power of regression to discriminate among various factors
associated with outcomes. I note that software presently available
(SPSS and STATA) are not up to date with what triangulation-oriented
social scientists may want path analysis to do. I explore one
application of the proposed technique, arguing that path analysis is
like a zoom lens enabling several alternative views of the economy.
It is possible to integrate macro and micro causation using this
method. However fragility analysis does not help with the
epistemological difficulties associated with regression. Rather, a
non-positivist epistemology is required. I discuss standpoint
epistemologies and critical realism as better starting-points than a
pretense of a factual narrative. With these modifications, the
analysis of statistics can be part of empowering processes in society.
Economists analysing cross-sectional and panel data usually presume the data represent a closed system. Once one relaxes the assumptions that distinguish closed from open social systems, the interpretation of statistical results must be less inferential and less firm than is conventionally the case. In section 1 I set out this position and argue that feminists of the main post-empiricist varieties (i.e. standpoint theorists and post-structuralists) can use statistical work as a way of telling stories that constructively contribute to knowledge; these stories may challenge or complement existing orthodoxies. In section 2 I set out some details of path analysis and I explain why at present one must arduously incorporate dummy variables into the results by hand instead of using a dedicated software package such as AMOS or LISREL (the SPSS adjuncts; see Norusis, 1998). In the third section, I explore a few from the wide range of possible economic applications of this technique. I argue that path analysis is like a zoom lens enabling the researcher to use a wide-angle lens as well as a telephoto lens or close-up view of socio-economy – integrating macro and micro instead of separating them. In section 4 I give a brief example using Indian farm-level data to raise policy issues about banking practices and security of land tenure. Finally, I conclude with a list of possible achievements that post-positivist statistics may be able to offer if the data-collection process occurs while path analysis is kept in mind as one way of summarizing the results into a story. I also mention other statistical techniques that may have promise for critical realists. All these suggestions are made on the premise that statistics are only part of multi-method triangulated research strategies (see also Yeung, 1997).
Section 1: Introduction
Critical Realist Statistics. Approaching statistics as a feminist or radical economist, one may tend to be rather pessimistic about what can be achieved. Critical realists in particular have been very skeptical about the positivist epistemology and flat ontology underlying inferential statistics. The falsification epistemology, which is the best that positivism has to offer, tends to ignore completely the transitivity of social objects (Sayer, 1992, chs 1-2; Smith, 1998, ch. 1 on the subject-object problem). That is, the creation of data using a survey method always presupposes a set of discursive practices which effectively shape and limit what the positivist can study and therefore place barriers around any falsification that may take place. Realists, such as W. Outhwaite in particular, argue that a more profound debate can occur -– apart from falsification but tending to place doubt upon it –- through a hermeneutic analysis of the meanings social objects and structures have for people (Outhwaite, 1987; see also Sayer, 1992). Only a very complex structuralism with explicitly embedded agents can survive the addition of a discursive or hermeneutic dimension to epistemology. The search for causal laws through constant conjunctions observed in data must end (Lawson, 1997). Agency cannot be reduced to rationality and we should not just seek empirical evidence to verify prior assumptions –- especially those based on simple deductive models like game-theory, rational-choice theory, or utility-maximization.
So if systems are open, then what is left to study via the survey method? Here are three items (and see Conclusion for more).
-
Examine How Disaffection Influences The System. People and other social units may be dissatisfied with current outcomes or choice sets, so they may try to alter some institutions or structures to change the system. See Olsen, 1998a, where the disaffection situations are seen to lead to choice paradoxes, or Olsen, 1998b: 24. There are also many cases where a choice paradox can lead to change or confusion in the discourse(s) in which people engage.
-
Investigate preferences and preference-formation directly, not indirectly (Young 1997). Enquire about opinions, strategies and reasons for doing or not doing things.
-
Explore Conflicts and Assume Dialectical Contradictions Occur. Structural locations clash in their 'effects'; opinions at different units of analysis may not coincide (notably employee versus firm level strategies, but also individual vs. household; see Doss, 1996). Outcomes may tend to mask conflicts. (Olsen, 1999b, stresses that people create collectivities partly in order to create situations in which they can take constructive action instead of merely resolving a contradiction using the existing 'choice-set'.)
As a result of these possibilities, social scientists from a range of disciplines have recommended triangulation, the collection of evidence using three or more vantage points. These 'angles' on the research project are actually data-creation routines that shape the researcher's experience and make possible a variety of data-analysis procedures such as qualitative analysis, graphic, and statistics. The analysis stage helps to make the conclusions seem legitimate to audiences, and the triangulation also enables claims of falsification, encompassing (Cook, 1999), statistical inference, and justification of specific claims to be made on the basis of the evidence constructed. In this paper I am focusing on the role of statistical inference in such a mixed-evidence approach.
Interpret Statistical Significance Only Probabilistically and Very Fallibilistically. The statistical significance tests are taught as being set up under the following conditional framework: "If all the assumptions required by the mathematics hold, and assuming the model is correct, then the significance level is the probability of being wrong in rejecting a null hypothesis regarding the population from which the sample is drawn." The statement has to be rephrased because the model cannot be 'correct'. It appears closed and therefore does not exactly fit the open system of the social world. We are left with the confidence level as an indicator of the probability of being right in rejecting a null hypothesis if the world were simply the closed system described, and assuming a random sample from that world.
The econometric debate on data-generation processes recognizes the limits to knowledge of the world that can be gained from the data, but I have not read authors in that tradition who advocate adding qualitative data to the armoury for interpretation, e.g. for choosing the 'best' or better model from among a variety of possible econometricmodels. I take regression models as a case study in this paper although there are many other types of model.
The size of each coefficient in regression can be interpreted as an estimate of the degree of association of two measured variables, within the given data (not inferring to the wider population from which the data are drawn). Different combinations of variables can be seen as having higher or lower degrees of goodness of fit, given the way the model offers a crude approximation of net aggregate outcomes in a complex closed system. Significance levels are down-graded in importance and cannot be a firm factor deciding the inclusion or exclusion of a variable in a model.
Closure cannot be assumed. No model depicted on paper can represent all the causal mechanisms in the social world, nor can it exhaust the relevant ones for a given study. Lawson (1997) in particular has argued that social systems are open systems. As a contrast, the deductive models of neoclassical theorists such as Stiglitz and Becker are essentially closed-system models with results purely contingent upon that closure.
A major barrier to closure is the dynamic relationship between agency and structure, i.e. the ability of a person or institution to rebel against given circumstances and to try to change or resist the system. Another is the complex web of social networks (institutions and organisations) that play a role between individual agency and structure. The structure-agency diagram used by Bhaskar (1979: 46) and recapitulated by Sayer (1992) and Smith (1998: 306 and 315) understates the importance of units of analysis. For example, household and families are units of analysis in themselves, and structures such as those of patriarchy also operate 'between' (ie interacting with) individuals and society. Such change processes, and the closely related form of feedback that more usually reproduces the existing social structures can be crudely and partially captured in complex data sets.
Discourse and collective action both affect outcomes in ways not predictable simply by static or closed models. Why are economists reluctant to allow for open systems? One main answer is perhaps that it complicates empirical work. The closed-system assumption enables the theorist to reject hypotheses not actually supported by given data. The clarity and replicability of a positivist's technique and conclusions are often seen as superior to the confused scene of complex intentionality that a critical realist might describe. Many critical realists are at present shunning multi-variable regression altogether because it intrinsically seems to imply a false closure of the social system (Porpora, 1998).
Stability of Coefficients Unlikely. The positivist discourse that pervades social statistics can, however, be challenged. In that discourse a random sample is crucial and statistical significance is defined as the probability of being wrong in rejecting a quantitative null hypothesis about the population, using the data in the random sample. It is also the chance of a given tendency having appeared merely as a result of random variation among the sample, given the sample size and making several assumptions about the variables in question. Statisticians usually want this probability to be very small, 10% or 1% for instance.
For these statistical tests to work, closure is essential; omission of any relevant variable will tend to cause an unpredictable bias in the other coefficients. The unpredictability is noted in every econometric or statistical text that covers multi-collinearity. Usually it appears only under that heading, but a new text by Mukherjee, Wuyts and White (1998) takes as a central theme the idea of choosing models that best fit given data by using "fragility analysis" (ibid., section 5.7) and other tests of assumptions as well as ensuring that the underlying theorization and operationalisation are adequate (i.e. complete descriptions of closed systems). These authors label as 'fragility analysis' the creation of a table of all the possible combinations of all subsets (of size 1, 2, 3, . . . up to k) of the k regression coefficients for a single regression. The table containing the coefficients under all specifications in the columns is examined to see how 'fragile' or sensitive each 'effect' is to the omission or inclusion of other effects. The authors recommend further exploring (especially graphing in a box plot) the bounds of these sets of coefficients.
Mukherjee, et al. (1998), in particular, have provided an exemplar to facilitate debate. The claim that fragility analysis can be used to choose between models is wrong for two reasons.
Firstly, the authors do not comment on the epistemological criteria that might be used to describe these results: which is the true coefficient, and how do we decide, from the range set by the fragility analysis? Which is the true model? Is the best we can do to choose from among a set of incomparable models? Either the choice is merely heuristic, or the models are merely illustrative. In either case, the 'testing' that comes elsewhere in the book (using standard statistical significance tests, later including the Durbin-Watson statistic and co-integration tests for time series) does not rest upon a consistent epistemological foundation. The choice rule hinted at by the fragility analysis section is either arbitrary, or unstated, or perhaps is open to the researcher's personal preference or prior expectations. Compare this ambiguous situation with the epistemological framework suggested by Sayer, 1992: 69-72. Sayer is to my knowledge unique in suggesting that economists and other researchers within narrow disciplines tend to use 'practical adequacy' as a way or arriving at epistemological criteria for given circumstances. Obviously such criteria are socially embedded and are continually changing. Sayer argues coherently against interpreting the predominance of practical adequacy in science as a rationale for ethical relativism. Rather, he argues, practical adequacy is inevitably used to simplify and select a focus for scientific results. He suggests reflexive consideration and discussion of the narrative basis for the selection criteria used. Communication of research, in his view, is part of ongoing social communications and social transformation.
Secondly, 'fragility analysis' does not resolve the problem that inevitably if any relevant variable is left out of a regression, the value of other coefficients will usually be profoundly changed. We should not expect a narrow range when exploring the bounds of the coefficients while openly omitting relevant multi-collinear variables. The effect on bi of omitting Xj is only negligible if Xj is correlated neither with Y nor with any other regressor (i.e. if it is orthogonal to them all).
If we assume regression is an attempt to capture net apparent effects of real causal mechanisms then it is important to be clear about whether we should expect stability in the coefficients over different specifications. In my view we should not expect it. My practical experience with data sets relating to opinion polls, food consumption, attitudes to food, agriculture, credit and sexual behaviours has convinced me that instability of coefficients is usual precisely because multi-collinearity is so common in social cross-sectional data sets. (There is also a separate argument about negative outcomes or non-occurrences, which may occur within a sub-group of a sample rather than across the whole sample; see section 5.) I am not commenting here on time series analyses where additional interpretive problems arise. Multi-collinearity in turn is common because of the multiple effects of structural influences such as resources and constraints (the latter called liabilities by Sayer, 1992, and Bhaskar, 1989). For instance, in industrial societies, household income is associated with lots of behaviours and attitudes because high income increases resources and low income creates felt constraints. A person's employment status is in turn imperfectly, but strongly, associated with income and then, both indirectly and directly, it influences behaviours and attitudes (see for instance Warde and Tomlinson, 1996, and Warde, Olsen and Martens, 1999).
For firms, similar multi-collinearity arises among firm size, choice of technology, marketing practices, strategies, etc.
In summary, only a positivist would seek to eliminate multi-collinearity from within one regression and then draw firm conclusions from the stability of coefficients. A realist has to be cautious even if coefficients appear to be stable. The best example of this in my work is that women are now widely said to be 'better repayers' of loans than men in developing countries. However the stability of the coefficient might not be that high if another correlated variable such as 'degree of concern with personal reputation as good bank customer' were inserted along with gender. The new variable would discriminate between committed repayers and others. The gender variable might then appear as statistically insignificant. In a sense any remaining 'gender' effect would reflect unexplained gender variation. As many methodologists have stressed, when there is a correlation the question is what could have caused that association (e.g Mukherjee et al., 1998: 118, 180-199). In addition, as banks lend to more women we can expect profound changes in women's banking behaviour so there is no stability in the open system outside the model, either. Thus one has to be cautious even if coefficients appear stable. The underlying system is open; it is not completely captured; it is changing; and it has contradictory tendencies not all of which are realised in snap-shot data sets. In addition, every cause has its own causes so every single regression inherently masks other things.
Standpoint Storytelling. Regression and various other techniques represent a form of standpoint storytelling. Compare it with Smith's account of other forms of storytelling (Smith, 1998: 279-299 et passim) such as positivist narratives which collapse prescriptive and descriptive elements into one allegedly factual narrative. It is dishonest to pretend otherwise (though as Aldridge has pointed out, positivists often try to withdraw from personal responsibility when they write up results; Aldridge, 1993). Compare any survey of feminist thought (e.g. Robeyns, 1998) with radical third-world participatory development methodologies (e.g. Fernandes, 1998), and one must conclude that standpoint theorising has a place in social science, including economics -- yet it must also be evidence-based in some way. From a given standpoint, set up through the survey method and reflecting only the character of the researcher(s) plus the sampled or surveyed social objects, what we can see is summarised by a regression or a graph. Of course, the underlying reality can be seen differently but we cannot do everything at once. Even in a triangulation strategy one often writes up the results in stages (describing the pilot, the survey, the qualitative component, the secondary data, etc., for instance). Open-systems interpretations of quantitative survey data analysis will tend to require in-depth data of other types, e.g. interviews, to augment the knowledge of the researcher.
Section 2: Path Analysis in Brief
One long-standing improvement upon single-equation multiple regression is the use of path analysis (Bryman & Cramer, 1995: 246 et passim). Several equations are set up and it is recognised that some variables are intermediate and play a part in two or more equations while others are so-called true independent variables. Yet other variables are seen as ultimate outcomes (dependent variables). It is obvious that path analysis cannot capture all the causes of the causes because they go a long way back and tend to have feedback (dialectically and over time) from some so-called 'outcomes'. It is also clear that path analysis sets up a closed system of equations but many authors do not recognise that this clashes with both an epistemological and an ontological notion of underlying open systems. For example, see the two-equation approach as applied to labour decisions among Ecuadorian peasants in Thapa, Bilsborrow and Murphy, 1996. I have written a brief critique of their model in Olsen (1998b).
Definition of Path Analysis. Path analysis usually gives a graphical presentation of the coefficients that measure or estimate the relative size and direction (+ or -) of various net effects between variables. The net effects are seen within a network of hypothesized causal mechanisms. There is one equation per outcome. One places the path coefficients onto the path diagram. These are comparable numbers such as -.69 or +.801 reflecting the estimated size of effects.
Path coefficients, in simple language, measure the standardized effect of an X on a Y. They measure how many standard-deviation units Y would go up by if X were increased by one standard-deviation. The use of standardized coefficients is handy because otherwise we would be comparing apples and oranges. The coefficient on land would be in units of acres, that on age would be in years, and so on.
The
path coefficients for multiple linear regression are labelled as
Beta-coefficients in computer output. These are calculated in the
following way:
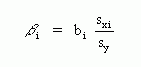 (Eq.
1)
(Eq.
1)
where Bi is Beta for independent variable Xi, bi is its regression coefficient, sxi is its standard deviation, and sy is the standard deviation of the dependent variable for that path. It turns out that an equivalent Beta is obtained by using the standard errors, rather than the standard deviations, of X and Y.
These Betas are comparable across the Xi's. They can exceed one and they can be negative. They do not add up to one. They can all be positive, as occurs if all the X variables have positive effects and the constant in each equation is negative or relatively small (see Figure 1). Usually most bs are less than one in absolute value.
Bryman
& Cramer recommend the inclusion of an error term as an
un-caused arrow leading toward each dependent variable in the figure.
The unexplained error term formula is :
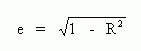 (Eq.
2)
(Eq.
2)
(Bryman and Cramer, 1995:246) Their advice is to admit that some 'error' is bound to remain 'unexplained'. Including the error arrow will also tend to offset the impression of a closed system. However, the quantification Bryman and Cramer suggest as e implies that the rest of the variation has been 'explained'. As my example of gender and loan repayment shows, however, correlation is not explanation so the numerical value of each coefficient, including e, is misleading.
Assumptions Underlying Path Analysis. I have pointed out in detail elsewhere that the comparability of the bs depends upon normal distributions of the underlying continuous variables (Olsen, 1998b). Dummy variables can be included, but if they occur anywhere as dependent variables in an equation, then AMOS and LISREL [the new and old SPSS modules for doing path analysis] cannot be used. AMOS does not enable the user to integrate logit, probit, or tobit regressions into models. (It does allow you to do bootstrap estimates if there are more than a thousand cases in the sample.) All equations in AMOS must use linear or curvi-linear regression at present.
The Heckman two-stage procedure, available directly as a short-cut in STATA software, is a form of path analysis (Heckman, 1992). Usually Heckman is used to examine first the factors associated with joining in a labour market and secondly the factors associated with (or affecting?) the extent of the labour market involvement. The latter is seen as labour market supply ex post. See Olsen, 1998b. If one sees Heckman procedure as a path analysis, then the possibility arises of extending it to include a detailed analysis of the demand-for-labour side in conjunction with the supply side. Whether demand can adequately be seen as separate from supply in labour markets is a difficult question. For people analysing commercialised labour markets (excluding farming, and perhaps also leaving out micro-enterprise and family-based businesses) the path analysis approach may be interesting. These are, however, large exclusions since small business can strategically affect any industry.
Other assumptions underlying path analysis as it is used for classic statistical inference are: random sampling, no heteroscedasticity, independence of independent variables from each other within an equation, and few enough missing values that no bias arises in the results from loss of cases.
Obviously path analysis can require a large data set with clear operationalisation, complete enumeration for all dependent variables, and careful scaling of any skewed variables. However it can also be used with lower-quality or simple data sets to illustrate an argument or a stage in an ongoing debate. The fundamental dissonance of apparent closure and actual openness is there, no matter how intensively measurement is carried out.
Path Coefficients When the Dependent Variable is a 0/1 (Dummy) Variable. If, say, logistic regression is used then the path coefficients from it are not the same as the bs from linear regressions when one interprets their absolute size (i.e. the extent of association). To some readers it may be obvious, but let me explain this a little (see also Menard, 1995).
Each bi in a logistic regression represents the effect of a unit rise in Xi on the log of the odds of Y occurring. Usually, authors present an adjusted coefficient, Exp(bi) which is the odds ratio between Xi and Y. The coefficients are derived from the following equations:
(a)
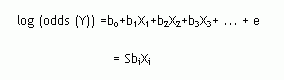 (Eq.
3)
(Eq.
3)
(b)
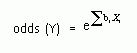 (Eq.
4)
(Eq.
4)
where S is the sum of the various direct effects of the Xi's on Y, including the constant term. The odds ratio Exp (bi) or ebi is usually presented as the main finding from logistic or probability regressions, as seen for instance in Rudkin (1993).
The standard deviation of the Y variable in this regression does not exist, so one cannot calculate Beta coefficients for logistic regression using the formula found in Equation 1 (Beta = bi (sxi / sy)). One can, however, transform the Xi's so that they are standardised.
Take Xi' xi/ sxi and use that instead of Xi in the logistic regression. The coefficients are then interpretable as follows:
(a) bi' is the effect of a one-standard-deviation rise in Xi on the log of the odds of Y.
(b) exp (bi') is the multiplicative effect of a one-standard-deviation rise in Xi on the odds of Y,
The Bi's can be added up; the exp (bi')'s or ebi's must be multiplied together to make sense.
Presumably in a path diagram we will use (a) not (b) above, and results from the equation 6 not equation 7 format. (Of course the two formats still reflect the same fit of a model and have the same level of statistical significance.) Therefore it behoves the analyst to mention that the effect of the X on the log-odds of Y will vary with the average odds of Y.
Interpretation of the Paths. Menard has solved the problem of estimating logistic regression Beta coefficients (see Olsen, 1998b: 17-18, or Menard, 1995: 46-48). I have also discussed latent variable analysis elsewhere (Olsen, 1998b: 18-20).
One can thus produce a path diagram using linear Betas and standardised logit coefficients. They cannot be multiplied together, but they can be interpreted. Their significance levels are also comparable, although it should be stated that the statistical test used is the Wald test in logistic regression versus the t-test in linear regression. In both cases the formula is simply that the test statistic is the coefficient divided by its standard error.
Omitted-variable bias can cause masking of real causal mechanisms in the original model. Statisticians know this so they recommend adding all relevant variables until the full (closed) model is set up. However in practice the addition of new variables is limited by the increase in multi-collinearity that often occurs at the same time. Such multi-collinearity often has its roots in social-structural causation but that does not make it any less problematic. If the Xi's are correlated then the bi's may be exaggerated and unstable.
It is said that in a 'good' model the addition or removal of one variable will not alter the size of other coefficients profoundly, but in the presence of multi-collinearity such instability is common. In positivist textbooks you will find statistical tests for collinearity. One set of tests is used in linear regression and another set of tests for logistic and Tobit regression (Mukherjee, White and Wuyts, 1997, chapters 6 and 11, for linear regression models; and see Menard, 1995, chapter 4, or Aldrich and Nelson, 1984, for logistic models). All these authors point out that resolving multi-collinearity involves choosing which variables to omit either on a priori or on statistical grounds. Realism will tend to make analysts use theoretical grounds for selecting or dropping variables rather than a technical criterion of best-fit or a rigid statistical significance cut-off level.
Critical realists would also expect to see imperfect 'fits' of data to models for a variety fo reasons. Causal processes are not deterministic in a complex, changing society. Many events are unique and events in society are not easily categorised into simple typologies (e.g. drug addict vs. not a drug addict). Critical realists are wary of ideal types yet ideal typologies are frequently used in statistics, expressed as categorical variables such as 'ethnic group' or 'marital status'. Ideal typologies lie in old or new discourses, and the realist would analyse these discursive practices rather than merely reifying them (Outhwaite, 1987).
Apart from this recognition of the phenomenological dimension of the researcher's own phraseology, one can also develop a realist interpretation of the statistical significance values for regression coefficients. In path analysis b values are monotonically related to statistical significance levels for a given equation and sample size. For instance, çbç's over .5 are nearly always highly significant. The reason is that b is directly related to the t-statistic in linear regression. The specific relationship between b and t is complicated. An equation representing this relationship is given in Olsen, 1998: 26, and leads to the following interpretation:
- b depends on variance of Xi (positive relationship);
- b depends on goodness of fit (positive relationship);
- b depends on variance of Y (positive relationship);
- b rises directly with t;
- b is reduced if multi-collinearity is large;
- b rises with n, the sample size, and falls with k, the number of regressors.
In other words, standardised regression coefficients help to demystify statistical significance and to enable readers to compare the relative sizes of measured effects. This will not resolve the problem that the model is bound to have some omitted variables (i.e. the world is an open system) but it downplays the role of sampling and tells us instead about what was apparently happening which had quantitative significance among the surveyed cases.
After all, if a study has 215 respondents representing 180 families, three labour-market segments and just three industries, then is N=215, or 180, or 3? With multiple units of analysis it becomes harder to sustain the myth of random sampling (Olsen, 1992) or the claim to universality of tendencies discovered. A discourse of complex descriptive statistics can substitute for the more commonly found discursive practices of inferential statistics.
A subjunctive interpretation is all that is possible. The significance level is the estimated probability of being wrong in claiming that a coefficient is non-zero if the world were simply the closed system described in the model, and if these cases were a random sample from that simple world, and if the normality and homoscedasticity assumptions were met and multi-collinearity were zero. The subjunctive tense can be used (it would be this probability if the world were like that) but a more firm claim about the world is not justified by the statisticsal data analysis. The inference is not factual.
For this reason I propose a significance cutoff level of 50% instead of 10% or 1%. The 50% level suggests that the odds would be just better than even that the apparent association was not just the result of random variation among the units sampled, under all the above assumptions.
The realist interpretation proposed here resolves the major dualism posed by statistical textbooks. This dualism is the idea that statistical inference can only be made based on random sample data sets, while no inferences at all can be drawn from non-random data sets. Like many dualisms in Western thinking, this one is somewhat limiting and can be avoided by a bit of re-thinking and re-phrasing.
Causal Mechanisms. Another unresolved issue is whether one can allow a mixture of structural and voluntary causal mechanisms. One might naively suggest these will tend to be unconscious and conscious mechanisms, respectively, but that is not strictly the case because the latter pair can overlap and/or conflict. If a strategy is highly correlated with a structural location, then introducing both as variables may enter an unnecessary complexity into a model. Double-representation of one causal mechanism by two variables will introduce instability into model coefficients (due to collinearity) or will weaken the two coefficients in so far as the variables are not perfectly correlated. Therefore caution must be used when introducing agency alongside structure. When you have multiple intersecting structural causes other problems arise (e.g. age and ethnicity; age and gender). Here interaction effects may need to be measured (Mukherjee, White and Wuyts, 1988:293-4). These require the intentional introduction of some collinearity since X1 * X2 is correlated with both X1 and X2. Yet interaction terms can improve models. For all the above reasons modelling needs to be seen partly as a heuristic art of creating a new narrative out of existing data. My story leads to others changing their stories. Our agreements and disagreements are part of social change processes.
Section 3: The Uses of a Zoom Lens
The applications of a path analysis approach in economics are many. The method can be used in demand-supply analysis; in the study of production; in labour economics (incorporating both behavioural and strategic struggle/resistance factors by creating new novel data sets), in studies of consumption, (e.g. see Olsen's (1998b) extension of the Olsen, Warde and Martens logistic models (1999) versus the more flat, single-regression structuralist model of Warde, Olsen & Martens, 1999) and even to tease out the influence that private information (which Stiglitz calls information asymmetry) gives to certain individuals or organisations.
It seems that now a whole range of specific econometrics techniques such as co-integration and the Heckman procedure need to be taken up in detail by critical realist economists who would use new, non-positivist criteria for including or excluding variables and altering the models. A recent heterodox volume in agricultural economics (Harriss-White, ed., 1999) tends to suggest that raw primary data will be more commonly needed once such a strategy is embarked upon. Economists then join the ranks of other social scientists who argue about the quality of innovative data sets and are both critical sceptical of government data (e.g. Marsh and Stoker, 1997 in political science; Gilbert, ed., 1993 in sociology). Most such pluralists today also use triangulation (ibid.) Discourse analysis takes a seat on centre stage alongside secondary and primary data analysis. Texts like de Vaus (1991) and Frankfurt-Nachmias and Nachmias (1996) cling to an out-dated, one-sided, non-qualitative positivist empiricism.
Complex demand-supply analysis using paths will need a lot of variables, and the resulting path diagram may be very complex (cf. Mair, 1989). On the other hand, simple, parsimonious (!) demand-supply analyses will almost certainly downplay actual effects of social structures and existing institutions above the individual unit of analysis. Simple path regressions will tend to downplay demand-supply interactions and may not give good estimates of elasticities.
It may be intriguing to examine the ex ante views of agents about market outcomes. Why should a data set contain only records of past events? One can ask people about their plans or strategies; firms can give records not only of output but also capacity and planned investments. Path analysis of the sources of outcomes like low-capacity-utilization or rapid-growth-plans can take into account a complex chain of causation. One can also find out how price expectations affect firm output (and how wage expectations influence the supply of labour).
One can integrate labour, input and product markets into the model; I give a diagram in Olsen, 1998b. However each author would explicate a model as they see fit in a given set of social economic and political circumstances. The shape of a model will not be universally derived by deduction from first principles (as in the debate surveyed by Cook, 1999), but rather will reflect current local concerns plus contemporary structural and ideological factors.
In summary, complex analysis of social structures can be combined with demand-supply analysis but several markets will generally be involved and heuristic decisions must be made to keep a model manageable.
The heuristic decision of an economist who is both exploring and illustrating her or his points is similar (discursively and epistemologically) to a photographic artist deciding where to stand, on what to focus, how far to zoom in, and how to set the light-opening width (aperture) which determines the quality, appearance and areas of clarity of a view of a scene. Scene-making? Story-telling? One begins to see an artistic aspect to the economist's activities. Economic anthropologist such as Ram (1992) and economic development specialists such as Mikkelson (1995) are already encouraging multi-disciplinary, multi-sourced, multi-media descriptions of economic arrangements in specific societies. Harriss-White goes so far as to argue that such primary studies are superior to deductive theorising (Harriss, 1979 and Harriss-White, 1999, op cit.). They are like using colour film rather than black & white film.
I have been exploring the use of path analysis as one way of getting a snap-shot of micro-enterprise and small business. Of course, such an exercise does not in itself do justice to the complex debate that is going on between neo-liberals advocating microenterprise versus marxists and feminists who often see it more critically as an ideological move within capitalist self-legitimisation strategies.
But micro-enterprise examples tend to illustrate the notion of emergence that is central to current realist thought. Properties of objects, such as households or farms, emerge not only from the properties of the underlying units, such as individuals. Rather, the collective unit is named and focused upon precisely in order to capture specific aspects which appear only when it is seen as a whole. (This is holism; see Warner, 1993). The book-keeping and banking practices of a firm for instance, are separate from and not necessarily the same as the record-keeping and banking practices of each person in the firm. It is relevant to note that in western industrial countries the book-keeper for a small firm or farm is much more likely to be a woman than a man; see Delphy and Leonard (1992). We should not expect a simple progression from smaller to larger units of analysis without indirect links and feedback between them. "Emergence" is thus a term reflecting the great complexity one can expect in any sophisticated study of multiple social units of analysis.
For this reason I give in the next section a brief summary of one study of one major 'micro-enterprise' sector: semi- and un-industrialised farming.
Section 4: An Example Using Indian Farm-Level Data
The following example from my research in South India illustrates how path analysis can transform a rather routine analysis into something revealing.
Methodology. I have been analysing data on 392 loans taken by people in one year in a random sample survey of 116 agrarian households -- landless labourers, farmers and a few landlords. The data came from southern Andhra Pradesh and have been reported on elsewhere (Olsen and Uma Rani, 1996 and 1997; Olsen, forthcoming book). In the 1996 report we stated that total debt of a household was clearly strongly associated with that household's land ownership and operational landholding. We knew at that stage that tenants' debts were different from those of larger land-owners, since some tenants had tied loans from their landlords and other tenants told us, during interviews, that there was no point asking them about bank loans because they were not eligible for them unless they owned land or gold to put down as collateral. Sarap had also shown that bank debt rose with landholding but fell with tenancy among 250 Orissan farmers in the 1980s (Sarap, 1990).
I have examined the debts of tenants and landowners, recognising that many households both own and rent a little land. Figure 1 illustrates the role of tenancy and specific investments which affect how, and to what extent, households borrowed from banks and on the informal credit market. I found strong ex post evidence that making investments and having a marriage increased the demand for credit; that borrowing from a bank was strongly associated with land ownership per se, as well as with investments; and finally that tenants were likely to be unable to access bank loans and instead were using the informal credit market to finance investments. These results need a little more investigation, since to my surprise they revealed that tenancy was positively associated with growing sugarcane. How is the irrigation financed on the sugarcane fields -- by the owner or by the tenant? The path analysis shows land ownership to be associated with digging new wells. To what extent do landlords invest in the land that is sharecropped; who gets the extra benefit from these investments; who makes the cropping pattern decisions on the share-cropped and cash-rented land? These new questions relate directly to the elasticity of supply of specific crops to price changes during the structural adjustment period (a subject which was outside of the immediate focus of the 1994-96 research).
A cautious interpretation of these findings is required. Like Sarap and others, I have incorporated personal and household factors where possible such as "the percentage of household members who can read or write". However different subsidised loan schemes (IRDP, DRI) were not indicated as such in the data, and men's and women's loans were not distinguished either2. What does become clear, however, is that the straightforward calculation of elasticities from closed-system models is highly questionable. Not only are some factors inevitably omitted, but in addition reverse causation may apply. For instance Khandaker Qudrat-I Elahi has calculated the elasticity of output supply to credit inputs, allowing for fertiliser and other inputs, but this seems to ignore the way the demand for credit is itself affected by crop-investment strategies.
Full details of all coefficients are in Olsen, 1998b, Appendix B.
Interpretations. Having resolved the technical problems raised by combining linear regression with logistic regression in path analysis, I can now draw some interpretations out of this particular model.
Gender is masked here since land ownership and agrarian investment are widely perceived to be household, not individual, decisions.
Land owned is a major factor influencing or enabling households to invest in crops and to get bank loans to finance such activities. Nearly all farmers grew groundnut and/or rice so these common crops are not shown as investments here. Innovation away from traditional crops is clearly facilitated by bank loans. A query arises as to the causal process here; it (A) or (B) below, or both?
I recall being taken by a bank manager to visit a cocoon-making family in the village of NPL in 1987. The bank manager wanted to introduce me to the male head of that household because, in his words, "In these villages no one wants to do anything. You come and meet this mulberry grower who uses our bank and takes advantage of our schemes." The banker saw this farmer as unusually entrepreneurial. Which came first here -- the demand for debt or the supply of a loan to him?
Bank loans and informal-sector loans are obviously close substitutes from a borrower's viewpoint, except for the higher interest rates and attached conditions like tied labour or beck-and-call labour sometimes imposed by lenders (Dacorta and Venkateswarlu, 1999). Family members of an indebted person may also be called upon to work in certain ways, and research up to now has not captured such household ties in much detail.
In sum, the decomposition of the apparent "effect" of landholding on debt has raised important questions about tenants' access to banks and ability to invest.
Fragility Analysis. In order to apply the economtricians' 'fragility analysis' to a path analysis, one would have to compare the coefficients for each equation under each possible specification. For the dependent variable at the right-hand side in Figure 1, for instance, 'log of informal-sector debt', there are 31 combinations of the five variables that lie as intermediate factors in the path diagram. These intermediate variables would then each have their own fragility analysis. I can supply the results at the conference but the epistemological basis for choosing from among all the different models, with their different sets of coefficients and different significance levels, is unclear. Fragility analysis does not offer a solution to the problem of the non-factuality of statistical inferences in such a case study.
Section 5: Conclusion (An Agenda for the Zoom Lens)
It is time to turn away from my Indian example and toward some general conclusions.
Other Techniques. Firstly, path analysis is just one technique that can be co-opted from inferential statistics for use by critical realists and other post-positivists. See my paper on credit market paradigms, for example, where simple bar charts have been integrated into a theoretical analysis using qualitative data and an analysis of discourse for triangulation (Olsen, 1998a). Other techniques that may be rescuable include: factor analysis, cluster analysis, and the use of control groups in regression. In medicine, for example, blind control groups will remain crucial, although, as Krieger (1994) explains, a social context must be provided.
On the other hand, examining the co-integration of price series will be unlikely to prove as interesting as its current proponents would suggest (see Indian Journal of Agricultural Economics, 1998, where six un-integrated fish markets are assumed to be uncompetitive; and see Khan & Hasan, 1998, for a macro-economic example testing the financial repression model). There are two reasons. Firstly, time series data rarely cover a long enough period for the assumptions regarding normality of the distribution of the series to be examined, let alone for the assumption to be found 'true' -- especially in studies of annual data, as admitted by Mukherjee, et al. (1993: 352). Secondly, even in monthly or weekly analyses where the data set is larger in the time dimension we would also, concurrently, need a wide range of associated data at different units of analysis in each time period. The analysis would then become a true panel data study in which the presence of co-integration plays a lesser role and regression techniques (and interpretation) are themselves crucial. See Olsen (1999a) for arguments tending to support the creation of panel data sets for the study of agricultural price movements. However, even here, the tension between the positivist discourse and post-positivism is evident from the differing positions other authors in the same book take regarding sampling. McGrath, for instance, urges random sampling of market transactions (in ibid., 1999) yet that seems intrinsically impossible due to the lack of a sampling frame (cf. Olsen, 1992).
Examples of Critical Realist Scientific Techniques and the Dangers of Reification. Taking regression and path analysis alone, several types of discoveries can be achieved by non-deductive narratives based on survey evidence. I list these below.
- Exposing the role of opinions and reasons as causes; Likert scales can be used;
- Exposing
hidden structural mechanisms
- obvious ones like class, often hidden for instance in medical studies in favour of ethnic variables (Harding, 1990);
- un-obvious ones seen in interaction effects;
- un-obvious ones revealed through decomposing complex objects to reveal their complex internal structure; notably the couple and the household;
- Pointing to new interventions or new/unrecognized actors (but for logistic regression at least 15% of cases must have Y=1); control groups and comparative groups can be used;
- Exploring negation and non-occurences, e.g. tenant farmers not getting bank loans in the Indian example in Section 3 of this paper.
In summary, critical realist statistics can play an un-masking role but its epistemology has to be profoundly different from that of conventional positivist statistics. Reification of things is inevitable since words convey meanings that are sometimes more enduring than the social objects they are meant to represent. However excess reification (e.g. the deification of demand and supply, or fetishism of commodity prices as powerful 'actors' in markets) needs to be avoided.
![]()
References
Aldrich, J.H. and F. D. Nelson. 1984. Linear Probability, Logit, and Probit Models, Sage: London.
Aldridge, J. 1993. "The Textual Disembodiment of Knowledge in Research Account Writing", Sociology, 27:2, 53-66.
Becker, G. 1974. "A Theory of Marriage: Part I", Journal of Political Economy, 81: 813-46.
Becker, G. 1981. A Treatise on the Family, Harvard Univ. Press, Cambridge.
Bhaskar, Roy. 1989. The Possibility of Naturalism: A Philosophical Critique of the Contemporary Human Sciences, Harvester Wheatsheaf, UK, and Humanities Press, New Jersey. (1st edition dated 1979).
Bryman, A. 1988. Quantity and Quality in Social Research.
Bryman, A., and D. Cramer. 1995. Quantitative Data Analysis for Social Scientists, Routledge, London, 1990, reprinted 1992, 2nd ed., 1995).
Collier, A., 1994. Critical Realism: An Introduction to Roy Bhaskar's Philosophy, London: Verso.
Cook, S. 1999. "Methodological Aspects of the Encompassing Principle", Journal of Economic Methodology, 6:1, pp. 61-78.
De Vaus, D. A. 1991. Surveys in Social Research, 3rd ed., UCL Press, London.
Elahi, K., Qudrat, 1995. "Impact of Institutional Credit on Paddy Production in Bangladesh", Journal of Rural Development, 14:3, pp.241-260.
Ellis, F. 1988. Peasant Economics: Farm Households and Agrarian Development, Wye Studies, Cambridge Univ. Press.
Feminist Economics, 1999. Special issue in honour of B. Bergmann.
Fernandes, W. 1998."Experiments in Creative Research: Efforts to Combiune Participatory with Conventional Methodology", Review of Development and Change, 3:2, July, 297-312.
Figart, D.M., 1997. "Gender As More Than a Dummy Variable: Feminist Approaches to Discrimination", Review of Social Economy, 55:1, pp. 1032.
Frankfort-Nachmias, C., and D. Nachmias, 1996. Research Methods in the Social Sciences, London: Arnold.
Gilbert, N. 1981. Modelling Society: An Introduction to Loglinear Analysis for Social Researchers, London: Allen & Unwin.
Gilbert, N., ed. 1993. Researching Social Life, London: Sage.
Granovetter, M., 1985. "Economic Action and Social Structure", American Journal of Sociology, 91, pp. 481-510.
Harding, S. 1990. The 'Racial' Economy of Science: Toward a Democratic Future, Bloomington: Indiana Univ. Press.
Harriss, B. (1979b). "There is Method in my Madness: Or is it Vice Versa? Measuring Agricultural Market Performance", Food Research Institute Studies, Vol. XVII, 2.
Harriss-White, Barbara. Forthcoming. Markets, Society And The State: Problems Of Marketing Under Conditions of Smallholder Agriculture in West Bengal, Sage, Delhi.
Harriss-White, ed., 1999. Agricultural Marketing From Theory to Practice: Field Experience in Developing Countries, London, Macmillan.
Heckman, J.J. 1992. "Selection Bias and Self-Selection", in Eatwell, J. et. al., The New Palgrave Econometrics, pp.201-224, London. Macmillan.
Indian Journal of Agricultural Economics 1998. Annual conference special issue, 53:3.
Khan & L. Hasan, 1998. "Financial Liberalization and Savings in Pakistan", Economic Development and Cultural Change, 46:3, April.
Krieger, N. 1994. "Epidemiology and the Web of Causation: Has Anyone Seen the Spider?", Social Science and Medicine, 39:7, pp. 887-903.
Lawson, T. 1996. 'Developments in "Economics as Realist Social Theory"', Review of Social Economy, LIV: 4, pp. 405-422.
Lawson, T. 1997. Economics and Reality. London: Routledge.
Marsh & Stokes, 2nd ed. (textbook on methodology for political scientists)
McGrath, P. 1999. "The Post-Harvest System in Indonesia", ch. 4 in B. Harriss-White, ed., 1999.
Menard, S. 1995. Applied Logistic Regression Analysis, Sage: London.
Mikkelson, B. 1995. Methods for Development Work and Research: A Guide for Practitioners, London: Sage.
Mukherjee, C., H. White, and M. Wuyts. 1998. Econometrics and Data Analysis for Developing Countries, Routledge, London.
Norusis, M. 1998. SPSS For Windows: AMOS Module User's Manual. SPSS Ltd., UK.
Olsen, W., and Rani Uma. 1997. "Preparing for Rural Adjustment", Monograph No. 2, Development and Project Planning Centre, University of Bradford.
Olsen, W. K., and Uma Rani. 1996. "Preparing for Rural Adjustment", report to the Overseas Development Administration, 85 pp.
Olsen, W. K. 1992. "Random Samples and Repeat Surveys in South India", Chapter 4 in S. Devereux and J. Hoddinott, eds., Fieldwork in Developing Countries, Harvester Wheatsheaf.
Olsen, W.K. 1998a. "Paradigms in the Analysis of Credit: Structures and Discourses in South Indian Banking", Working Paper No. 5, Graduate School of Social Sciences and Humanities, University of Bradford.
Olsen, W.K. 1998b. "Path Analysis for the Study of Farming and Microenterprise: A Critical Realist Approach", Working Paper No. 22, Development and Project Planning Centre, Univ. of Bradford BD7 1DP.
Olsen, W. K. 1999a. "Village Level Exchange: Lessons from South India", ch. 2 in B. Harriss-White, ed., 1999.
Olsen, W.K. 1999b. "Empowerment Through Ideological Upheaval: Propositions from the Study of Banking Crises", paper for the Conference on Women and Political Action, Middlesex Univ., Middlesex, UK, June.
Olsen, W.K., A. Warde, and L. Martens. 1998. "Social Differentiation and the Market for Eating Out in the UK", Working Paper No. 3, Graduate School of Social Sciences & Humanities, University of Bradford. (Forthcoming in International Journal of Hospitality Management)
Outhwaite, W. 1987. New Philosophies of Social Science: Realism, Hermeneutics and Critical Theory, London: Macmillan.
Ram, K., 1991. Mukkuvar Women: Gender, Hegemony and Capitalist Transformation in a South Indian Fishing Community, Allen & Unwin, 1991 and Kali for Women, Delhi, 1992.
Robeyns, I. 1999. "Methodological Issues in Feminist Economics", mimeo for Workshop on Realism & Economics, Kings College, University of Cambridge.
Rudkin, L. 1993. "Gender Differences In Economic Well-Being Among the Elderly of Java", Demography, 30:2, May.
Sarap, K. 1990. "Factors Affecting Small Farmers' Access to Institutional Credit in Rural Orissa, India", Journal of Development Studies, 21, pp.281-307.
Sayer, A. 1992. Method in Social Science: A Realist Approach, 2nd ed., London: Routledge and Kegan Paul.
Sen, A. 1980. "Description As Choice", Oxford Economic Papers.
Skinner, C.J., D. Holt, and T.M.F. Smith. 1989. Analysis of Complex Surveys, Wiley: London.
Thapa, K.K., R.E. Bilsborrow, and L. Murphy. 1996. "Deforestation, Land Use, and Women's Agricultural Activities in the Ecuadorian Amazon", World Development, 24:8, 1317-1332.
Warde, A., L. Martens, and W. Olsen. 1999. "Consumption and the Problem of Variety: Cultural Omnivorousness, Social Distinction and Dining Out", Sociology, 33:1.
Warner, M.M. 1993. "Objectivity and Emancipation in Learning Disabilities: Holism From the Perspective of Critical Realism", Journal of Learning Disabilities, 26:5, May, pp. 311-325.
Yeung, H. W. 1997. "Critical Realism and Realist Research in Human Geograph: A Method or a Philosophy in Search of a Method?", Progress in Human Geography, 21:1, pp. 51-74.
Young, D. 1996. "Changing Tastes and Endogenous Preferences: Some Issues in Modelling the Demand for Agricultural Products", European Review of Agricultural Economics, 23, pp.281-300.
Copyright © 1999 Wendy K. Olsen
![]()
![]() The
WSCR Archive
The
WSCR Archive